1. 규칙기반 품사 태깅이란?
컴퓨터가 자연어를 이해하고 분석할 수 있도록 하는 자연어 처리 기술 중 하나인 품사 태깅은 문장에 포함된 각 단어에 대해 그 단어의 품사를 판별하는 작업입니다. 이러한 품사 태깅 작업을 수행하는 방법에는 여러 가지가 있지만, 그 중에서도 규칙기반 품사 태깅은 가장 전통적이고 기본적인 방법입니다.
규칙기반 품사 태깅은 문장의 구성과 문법 규칙을 기반으로 각 단어의 품사를 결정하는 방법입니다. 즉, 미리 정의된 문법 규칙을 사용하여 입력 문장을 구문 분석하고, 각 단어의 품사를 판별하는 방식입니다. 이러한 방법은 사람이 직접 문법 규칙을 정의하고 규칙에 따라 품사 태깅을 수행하기 때문에, 일정 수준의 정확성을 보장할 수 있습니다.
하지만 규칙기반 품사 태깅 방법은 문법 규칙을 정의하는 과정이 복잡하고 시간이 오래 걸리는 단점이 있습니다. 또한, 모든 경우에 대해서 정확한 품사 판별이 불가능하며, 미리 정의된 규칙에 벗어난 문장에 대해서는 제대로 처리할 수 없는 경우가 있습니다.
따라서 규칙기반 품사 태깅은 비교적 간단하고 직관적인 방법이지만, 정확도와 확장성이 떨어지는 한계가 있습니다.
2. 규칙 기반 품사 태깅 방법
규칙 기반 품사 태깅은 문장의 구성과 문법 규칙을 기반으로 각 단어의 품사를 결정합니다. 이를 위해서는 다음과 같은 단계를 거쳐야 합니다.
2.1. 문법 규칙 정의
먼저, 규칙 기반 품사 태깅을 수행하기 위해서는 문법 규칙을 미리 정의해야 합니다. 이를 위해서는 Chomsky Normal Form(CNF) 형식을 따르는 문법 규칙을 정의하는 것이 일반적입니다.
예를 들어, 다음과 같은 문법 규칙을 정의할 수 있습니다.
S -> NP VP
NP -> DT NN | PRP
VP -> VB | VBZ NP | VBZ PP
PP -> IN NP
DT -> "the" | "a"
NN -> "cat" | "dog" | "cookie"
PRP -> "I" | "you"
VB -> "saw" | "ate"
VBZ -> "eats"
IN -> "on" | "in"위 문법 규칙은 S(문장)을 NP(명사구)와 VP(동사구)로 나누는 규칙, NP를 DT(관사)와 NN(명사) 또는 PRP(인칭대명사)로 나누는 규칙, VP를 VB(동사) 또는 VBZ(동사)와 NP 또는 PP(전치사구)로 나누는 규칙, PP를 IN(전치사)와 NP로 나누는 규칙으로 구성되어 있습니다.
2.2. 구문 분석기 생성
다음으로, 구문 분석기를 생성해야 합니다. 구문 분석기는 입력된 문장을 구문 분석하여 문장 구조를 트리 형태로 나타내는 역할을 수행합니다.
구문 분석기는 정의된 문법 규칙을 기반으로 생성되며, 일반적으로 CKY 알고리즘을 사용하여 구현됩니다.
2.3. 입력 문장의 토큰화
구문 분석기를 사용하여 문장을 분석하려면, 먼저 입력 문장을 단어 단위로 분리하는 과정이 필요합니다. 이를 위해 입력 문장은 토큰화 과정을 거쳐 단어들로 분리됩니다.
2.4. 품사 태깅 수행
입력 문장이 토큰화되면, 구문 분석기를 사용하여 문장 구조를 분석하고, 각 단어의 품사를 판별합니다. 이를 위해서는 입력 문장의 각 단어가 문법 규칙에 따라 어떤 품사로 태깅될 수 있는지 분석합니다. 이후, 모든 가능한 품사 태깅 후보군 중에서 가장 확률이 높은 태깅을 선택하여 최종적인 품사 태깅 결과를 도출합니다.
이러한 규칙 기반 품사 태깅 방법은 자연어 처리 분야에서 다양한 응용 분야에서 사용되고 있으며, 간단한 자연어 처리 작업에 적용하기에 유용합니다. 그러나, 문법 규칙을 수작업으로 정의해야 하기 때문에, 정확성과 확장성에 제한이 있으며, 다양한 문법 구조를 처리하기 어렵습니다.
따라서, 최근에는 머신러닝을 기반으로 하는 품사 태깅 방법이 주로 사용되고 있으며, 규칙 기반 방법과 머신러닝 기반 방법의 장단점을 비교하여 적절한 방법을 선택하여 사용해야 합니다.
3. NLTK를 이용한 규칙기반 품사 태깅 실습
NLTK는 파이썬에서 자연어 처리를 위해 널리 사용되는 라이브러리입니다. NLTK를 사용하면 규칙기반 품사 태깅을 쉽게 구현할 수 있습니다. 이번 섹션에서는 NLTK를 사용하여 규칙기반 품사 태깅을 수행하는 방법에 대해 알아보겠습니다.
3.1. NLTK 설치 및 준비
NLTK를 사용하기 위해서는 우선 NLTK를 설치해야 합니다. 파이썬 패키지 관리자인 pip를 사용하여 NLTK를 설치할 수 있습니다. 아래 명령어를 실행하여 NLTK를 설치합니다.
!pip install nltkNLTK 설치가 완료되면, NLTK에서 제공하는 샘플 말뭉치 데이터를 다운로드합니다. 샘플 말뭉치는 NLTK에서 제공하는 예제 문장 데이터로, 품사 태깅을 수행하는 데 사용됩니다. 아래 코드를 실행하여 샘플 말뭉치 데이터를 다운로드합니다.
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
3.2. 문장 입력 및 토큰화
먼저, 품사 태깅을 수행할 문장을 입력받아야 합니다. 아래 코드는 사용자로부터 문장을 입력받아서 토큰화하는 코드입니다.
import nltk
sentence = "This is example."
tokens = nltk.word_tokenize(sentence)
tokens3.3. 품사 태깅 규칙 정의
다음으로, 품사 태깅을 위한 규칙을 정의합니다. 아래 코드는 DT(관사), JJ(형용사), NN(명사)의 조합으로 이루어진 명사구(NP)와 V(동사)로 이루어진 동사구(VP)를 인식하는 규칙을 정의하는 코드입니다.
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> DT JJ NN | DT NN
VP -> V | V NP | V PP
PP -> P NP
DT -> "the" | "a"
JJ -> "big" | "red" | "tasty"
NN -> "cat" | "dog" | "cookie"
V -> "saw" | "ate"
P -> "in" | "on"
""")3.4. 구문 분석기 생성 및 품사 태깅 수행
마지막으로, 입력 문장에 대해 구문 분석기를 생성하고, 규칙에 따라 규칙기반 품사 태깅을 수행합니다. 아래 코드는 구문 분석기를 생성하고, 입력된 문장에 대해 품사 태깅을 수행하는 코드입니다.
import nltk
sentence = "The cat chased the mouse"
tokens = nltk.word_tokenize(sentence)
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> DT NN | DT JJ NN
VP -> V NP
DT -> "The" | "the"
JJ -> "big" | "red" | "tasty"
NN -> "cat" | "dog" | "cookie" | "mouse"
V -> "saw" | "ate" | "chased"
""")
parser = nltk.ChartParser(grammar)
trees = parser.parse(tokens)
for tree in parser.parse(tokens):
print(tree)위 코드에서는 입력 문장을 토큰화한 후, 정의된 규칙을 사용하여 구문 분석기를 생성합니다. 이후, 생성된 구문 분석기를 사용하여 입력 문장에 대해 품사 태깅을 수행하고, 결과를 출력합니다.
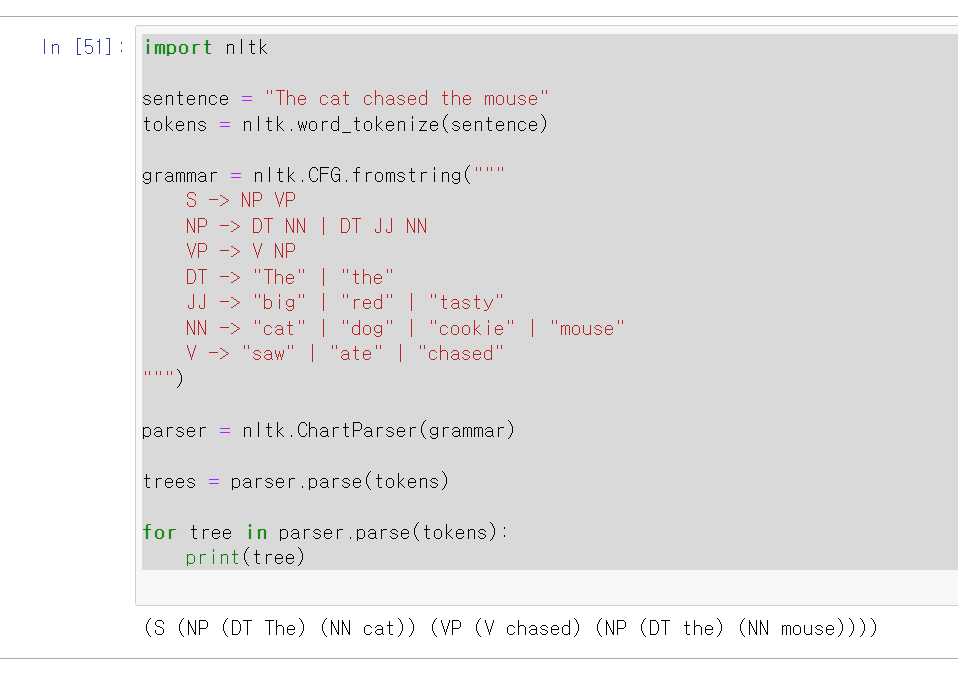
3.5. 결과 확인
아래는 입력 문장 "The cat chased the mouse"에 대해 규칙기반 품사 태깅을 수행한 결과입니다.
(S
(NP (DT The) (NN cat))
(VP
(V chased)
(NP (DT the) (NN mouse))))위 결과에서는 입력 문장이 NP와 VP로 분리된 것을 확인할 수 있으며, 각각의 단어들은 규칙에 따라 적절한 품사로 태깅된 것을 확인할 수 있습니다.
3.6. NLTK에서 제공하는 기본 태그셋
NLTK에서는 품사 태깅을 수행하기 위한 기본 태그셋을 제공합니다. 아래는 NLTK에서 제공하는 기본 태그셋 중 일부입니다.
- CC : 접속사
- CD : 기수
- DT : 관사
- EX : 선행사
- FW : 외래어
- IN : 전치사
- JJ : 형용사
- JJR : 비교급 형용사
- JJS : 최상급 형용사
- LS : 목록 마커
- MD : 조동사
- NN : 명사
- NNS : 복수형 명사
- NNP : 고유명사
- NNPS : 복수형 고유명사
- PDT : 전치한정사
- POS : 소유격 조사
- PRP : 인칭대명사
- PRP$ : 소유격 인칭대명사
- RB : 부사
- RBR : 비교급 부사
- RBS : 최상급 부사
- RP : 불변화사
- SYM : 심볼
- TO : to
- UH : 감탄사
- VB : 동사 (기본형)
- VBD : 동사 (과거형)
- VBG : 동사 (현재분사형)
- VBN : 동사 (과거분사형)
- VBP : 동사 (동사원형 이외의 현재형)
- VBZ : 동사 (동사원형 이외의 3인칭 단수형)
이 외에도 다양한 태그셋이 존재합니다.
NLTK에서는 기본 태그셋을 이용한 품사 태깅을 수행할 수 있도록 pos_tag() 함수를 제공합니다. pos_tag() 함수는 문장을 입력받아, 각 단어의 품사를 태깅한 결과를 반환합니다. 아래는 pos_tag() 함수를 사용하여 입력 문장에 대해 품사 태깅을 수행하는 예제 코드입니다.
import nltk
sentence = "The big red dog ate the tasty cookie on the table"
tokens = nltk.word_tokenize(sentence)
tagged = nltk.pos_tag(tokens)
print(tagged)위 코드에서는 입력 문장을 토큰화한 후, pos_tag() 함수를 사용하여 각 단어의 품사를 태깅합니다. 태깅된 결과는 (단어, 품사) 형태의 튜플로 반환됩니다. 출력 결과는 아래와 같습니다.
[('The', 'DT'), ('big', 'JJ'), ('red', 'JJ'), ('dog', 'NN'), ('ate', 'VBD'), ('the', 'DT'), ('tasty', 'JJ'), ('cookie', 'NN'), ('on', 'IN'), ('the', 'DT'), ('table', 'NN')]
위 결과에서는 각 단어에 대한 품사 태깅이 수행되어, (단어, 품사) 형태로 반환된 것을 확인할 수 있습니다. 예를 들어, 'The'는 관사(DT)로, 'big'은 형용사(JJ)로, 'ate'는 동사의 과거형(VBD)으로 태깅된 것을 확인할 수 있습니다.
4. 규칙기반 품사 태깅의 한계와 대안
규칙 기반 품사 태깅은 일반적으로 간단하고 직관적인 방법입니다. 하지만, 이 방법에는 몇 가지 한계가 있습니다.
4.1. 한계
4.1.1. 규칙 추가 및 수정의 어려움
규칙 기반 품사 태깅에서는 품사 태깅을 수행하기 위한 규칙을 사람이 직접 작성해야 합니다. 이는 규칙 추가나 수정이 필요할 때 매우 번거로운 작업으로 이어집니다. 또한, 새로운 언어나 도메인에 대한 품사 태깅을 수행하기 위해서는 전적으로 새로운 규칙을 작성해야 합니다.
4.1.2. 동음이의어 및 애매모호한 단어 처리의 어려움
규칙 기반 품사 태깅에서는 각 단어가 하나의 고유한 품사를 가지는 것으로 가정합니다. 하지만, 실제 자연어에서는 동음이의어나 애매모호한 단어가 많이 존재합니다. 예를 들어, "난 밥을 먹는다"와 "밥을 먹는다"는 같은 단어들을 사용하지만, 전자는 "나"가 "밥"을 먹는다는 의미이고, 후자는 "밥"을 먹는다는 의미입니다. 이와 같은 경우, 규칙 기반 품사 태깅은 어려움을 겪을 수 있습니다.
4.1.3. 문장 구조 변화에 대한 대처의 어려움
규칙 기반 품사 태깅은 문장의 구조가 변경될 경우, 품사 태깅이 잘못될 수 있습니다. 예를 들어, "나는 맛있는 사과를 먹었다"와 "맛있는 사과를 나는 먹었다"는 같은 단어들을 사용하지만, 전자는 "나"가 "사과"를 먹는다는 의미이고, 후자는 "사과"를 먹는 사람이 "나"임을 나타냅니다.
4.2. 대안
4.2.1. 통계 기반 품사 태깅
규칙 기반 품사 태깅의 한계를 극복하기 위한 대안으로, 통계 기반 품사 태깅 방법이 제안되었습니다. 통계 기반 품사 태깅은 훈련 데이터를 기반으로 각 단어의 품사 분포를 파악하고, 이를 바탕으로 새로운 문장에 대해 품사 태깅을 수행합니다. 대표적인 통계 기반 품사 태깅 알고리즘으로는 HMM(Hidden Markov Model)과 CRF(Conditional Random Field)가 있습니다.
4.2.2. 딥 러닝 기반 품사 태깅
딥 러닝 기술의 발전으로 인해, 딥 러닝 기반 품사 태깅 방법도 제안되고 있습니다. 딥 러닝 기반 품사 태깅은 입력 문장을 다층 신경망에 넣어 학습을 수행하고, 이를 바탕으로 새로운 문장에 대해 품사 태깅을 수행합니다. 대표적인 딥 러닝 기반 품사 태깅 알고리즘으로는 BiLSTM-CRF와 Transformer가 있습니다.
통계 기반과 딥 러닝 기반 품사 태깅은 규칙 기반 품사 태깅의 한계를 극복하면서도 높은 성능을 보입니다. 하지만, 이러한 방법들도 한계를 가지고 있으며, 각각의 장단점을 고려하여 적절한 방법을 선택해야 합니다.
5. 결론
규칙 기반 품사 태깅은 일반적으로 간단하고 직관적인 방법입니다. 하지만, 이 방법에는 규칙 추가나 수정의 어려움, 동음이의어 및 애매모호한 단어 처리의 어려움, 문장 구조 변화에 대한 대처의 어려움 등의 한계가 있습니다. 이러한 한계를 극복하기 위해, 통계 기반 품사 태깅과 딥 러닝 기반 품사 태깅 등의 다양한 대안 방법이 제안되고 있습니다.
따라서, 품사 태깅을 수행할 때에는 문제에 적합한 방법을 선택하여 사용해야 합니다. 단순한 문장에 대해서는 규칙 기반 품사 태깅이 적합할 수 있으며, 복잡한 문장이나 새로운 도메인에 대해서는 통계 기반 품사 태깅이나 딥 러닝 기반 품사 태깅 등의 방법이 더욱 적합할 수 있습니다.
하지만, 어떤 방법을 선택하더라도 정확한 품사 태깅을 위해서는 충분한 양의 훈련 데이터가 필요합니다. 또한, 품사 태깅의 정확도를 높이기 위해서는 전처리나 후처리 과정도 중요합니다. 따라서, 품사 태깅을 수행할 때에는 데이터의 양과 질을 고려하고, 전처리와 후처리 과정도 적절히 수행해야 합니다.
이 글을 ChatGPT의 도움을 받아 작성되었습니다.
'ChatGPT > 인공지능' 카테고리의 다른 글
| [자연어처리] Python을 활용한 POS 태깅 모델링: Hidden Markov Model 학습 방법 (0) | 2023.04.30 |
|---|---|
| [자연어처리][PYTHON] Peter Norvig의 베이지안 스펠링 체커 (0) | 2023.04.22 |
| [자연어처리][PYTHON] 통계기반 품사 태깅 (0) | 2023.04.21 |
| [자연어처리][PYTHON] 베이지안 추론 모델을 이용한 스펠링 체커 만들기 (0) | 2023.04.19 |
| [정보이론][엔트로피] - Entropy 소개 (0) | 2023.04.19 |



