베이지안 추론 모델을 이용한 스펠링 체커 만들기
서론
스펠링 체커의 필요성
스펠링 체커는 맞춤법 검사 등에 사용되는 자연어 처리 기술 중 하나로, 주어진 단어가 올바르게 쓰여졌는지 검사하여 틀린 부분을 찾아내어 올바른 단어로 교정해주는 기능을 한다. 스펠링 체커는 일반적으로 텍스트 에디터, 워드프로세서, 이메일 클라이언트 등에서 사용되며, 온라인 검색 엔진에서도 검색어의 오타를 자동으로 교정해주는 기능이 있다.
스펠링 체커는 일반 사용자들뿐만 아니라 비즈니스 분야, 교육 분야, 언어학 연구 등 다양한 분야에서 필요하게 사용된다.
베이지안 추론 모델 소개
베이지안 추론은 사후 확률을 계산하기 위해 베이즈 정리를 이용하는 확률적 모델링 방법 중 하나이다. 이 방법은 사전 정보를 가지고 주어진 증거에 따라 사후 확률을 계산하는데, 이를 이용하여 특정 상황에서 발생할 확률을 예측할 수 있다.
베이지안 추론은 자연어 처리 분야에서 스펠링 체커를 비롯한 다양한 언어 모델링에 활용되고 있다. 스펠링 체커에서는 베이지안 추론 모델을 이용하여 입력된 단어를 분석하고 후보 단어들 중 가장 확률이 높은 단어를 교정 단어로 선택하게 된다. 이러한 방법은 단어들 간의 관계를 고려하여 교정을 수행하므로 높은 교정 성능을 보인다.
데이터 준비하기
이번 프로젝트에서는 'big.txt'라는 파일을 사용한다. 이 파일은 영어 단어들의 모음으로 구성되어 있으며, 이를 이용하여 스펠링 체커 모델의 사전 확률을 계산한다.
파일을 읽어들인 후, 're.findall()' 함수를 이용하여 파일 내의 모든 단어를 추출하고, 모든 단어를 소문자로 변환한다. 이를 통해 대소문자 구분 없이 모든 단어를 처리할 수 있다.
다음으로, 추출된 단어들을 이용하여 모든 가능한 단어들의 사전 확률 값을 등록한다. 예를 들어, 'word'라는 단어가 주어졌을 때, 이 단어를 구성하는 모든 2-gram, 즉 'wo', 'or', 'rd' 등의 단어들의 사전 확률 값을 계산하고 등록한다. 이를 통해 입력된 단어와 유사한 후보 단어들의 사전 확률을 계산할 수 있다.
마지막으로, 'Counter' 함수를 이용하여 모든 단어들의 빈도수를 계산하고, 이를 이용하여 각 단어의 전체 확률 값을 계산한다. 이를 통해 사전 확률을 계산할 때 이용된 모든 단어들의 출현 빈도를 고려할 수 있다.
모델 구현
이제 입력된 단어와 유사한 후보 단어들의 사후 확률을 계산하는 스펠링 체커 모델을 구현한다. 이를 위해 다음과 같은 함수들을 구현한다.
- 'error_prob(error, letter)' : 에러 모델의 확률을 계산하는 함수
- 'error' : 에러가 발생한 문자
- 'letter' : 에러가 발생하기 전의 문자
- 반환값 : 에러 모델의 확률 값
- 'candidate_words(word)' : 후보 단어를 생성하는 함수
- 'word' : 입력된 단어
- 반환값 : 후보 단어 리스트
- 'posterior_prob(word)' : 사후 확률을 계산하는 함수
- 'word' : 입력된 단어
- 반환값 : 후보 단어들의 사후 확률 값을 담은 딕셔너리
위 함수들을 이용하여 스펠링 체커 모델을 구현할 수 있다.
먼저, 'error_prob()' 함수는 에러 모델의 확률을 계산하는 함수로, 'error'와 'letter'를 입력받아 에러 모델의 확률 값을 반환한다. 이때, 에러 모델의 값은 에러가 발생하기 전 문자('letter')와 에러가 발생한 문자('error') 사이의 변환 가능성을 나타내는 값으로, 에러 모델링 과정에서 사전에 정의되어야 한다.
다음으로, 'candidate_words()' 함수는 입력된 단어를 기반으로 후보 단어를 생성하는 함수로, 'word'를 입력받아 후보 단어 리스트를 반환한다. 이때, 후보 단어는 입력된 단어에서 하나의 문자를 변경하거나, 두 개의 문자의 위치를 변경한 결과로 생성된다. 이를 통해 입력된 단어와 유사한 후보 단어들을 생성할 수 있다.
이러한 방법을 이용하여 후보 단어들을 생성하면, 스펠링 체커 모델의 정확도를 높일 수 있습니다. 따라서, errors 딕셔너리는 스펠링 체커 모델에서 매우 중요한 역할을 합니다.
마지막으로, 'posterior_prob()' 함수는 입력된 단어와 유사한 후보 단어들의 사후 확률 값을 계산하는 함수로, 'word'를 입력받아 후보 단어들의 사후 확률 값을 담은 딕셔너리를 반환한다. 이때, 사후 확률 값은 베이지안 추론을 이용하여 계산되며, 후보 단어들의 사전 확률 값과 에러 모델의 확률 값을 고려하여 계산된다.
import collections
import re
def words(text):
return re.findall(r'\w+', text.lower())
# 사전 확률 설정
word_freq = collections.Counter(words(open('big.txt').read()))
total_words = sum(word_freq.values())
# 모든 가능한 단어들의 사전 확률 값을 등록
all_words = set()
for word in word_freq.keys():
for i in range(len(word)):
for j in range(i+1, len(word)):
candidate = word[:i] + word[j] + word[i+1:j] + word[i] + word[j+1:]
all_words.add(candidate)
for word in all_words:
if word not in word_freq:
word_freq[word] = 0
prior_prob = {word: freq / total_words for word, freq in word_freq.items()}
# 에러 모델링
errors = {
"t": ["r", "e", "h", "u", "y"],
"e": ["r", "w", "s", "d", "f", "g", "v", "c", "x", "z"],
"h": ["t", "y", "u", "j", "k", "l", "n", "m"],
" ": ["t", "e", "h"],
"k": ["c"],
"c": ["k"],
"s": ["a", "d", "w", "e", "z", "x"],
"a": ["s", "z", "x", "q", "w"],
"d": ["s", "e", "x", "c", "f"],
"w": ["a", "s", "e", "d", "q"],
"z": ["a", "s", "x"],
"x": ["z", "s", "d", "c"],
"f": ["g", "r", "t", "v", "c"],
"g": ["f", "t", "y", "h", "b"],
"r": ["e", "t", "y", "u", "f", "g", "h", "j"],
"t": ["r", "y", "u", "g", "h", "j", "k", "l"],
"y": ["t", "u", "i", "h", "j", "k"],
"u": ["y", "i", "o", "j", "k", "l"],
"i": ["u", "o", "p", "k", "l", "m"],
"o": ["i", "p", "l"],
"p": ["o", "l"],
"l": ["k", "j", "h", "o", "p"],
"j": ["h", "y", "u", "k", "l", "n", "m"],
"k": ["j", "u", "i", "l", "m"],
"n": ["h", "j", "m"],
"m": ["n", "j", "k"]
}
def error_prob(error, letter):
"""에러 모델의 확률을 계산하는 함수"""
if error == "":
# 글자 손실인 경우
return 0.1 # 임의로 0.1로 지정
return errors.get(letter, "").count(error) / len(errors.get(letter, ""))
# def candidate_words(word):
# """후보 단어를 생성하는 함수"""
# candidates = set()
# for i in range(len(word)-1):
# for j in range(i+1, len(word)):
# candidate = word[:i] + word[j] + word[i+1:j] + word[i] + word[j+1:]
# candidates.add(candidate)
# return list(candidates)
def candidate_words_1(word):
candidates = set()
for i in range(len(word)):
for c in errors:
if word[i] in errors[c]:
candidate = word[:i] + c + word[i+1:]
candidates.add(candidate)
return list(candidates)
def candidate_words_2(word):
candidates = set()
for i in range(len(word)-1):
for j in range(i+1, len(word)):
candidate = word[:i] + word[j] + word[i+1:j] + word[i] + word[j+1:]
candidates.add(candidate)
return list(candidates)
def candidate_words_3(word):
candidates = set()
for i in range(len(word)-2):
for j in range(i+1, len(word)-1):
for k in range(j+1, len(word)):
candidate = word[:i] + word[j] + word[i+1:j] + word[k] + word[j+1:k] + word[i] + word[k+1:]
candidates.add(candidate)
return list(candidates)
def candidate_words(word):
candidates = set()
# 단어의 길이가 1인 경우
if len(word) == 1:
for c in errors:
if word in errors[c]:
candidates.add(c)
# 단어의 길이가 2인 경우
elif len(word) == 2:
for i in range(len(word)):
for c in errors:
if word[i] in errors[c]:
candidate = word[:i] + c + word[i+1:]
candidates.add(candidate)
# 단어의 길이가 3 이상인 경우
else:
candidates |= set(candidate_words_1(word))
candidates |= set(candidate_words_2(word))
candidates |= set(candidate_words_3(word))
return list(candidates)
def posterior_prob(word):
"""사후 확률을 계산하는 함수"""
candidates = candidate_words(word)
posterior_prob = {word: prior_prob[word] for word in candidates if word in prior_prob}
for candidate in candidates:
for i, c in enumerate(candidate):
if c in errors:
for error in errors[c]:
corrected_word = candidate[:i] + error + candidate[i+1:]
if corrected_word not in posterior_prob:
continue
posterior_prob[corrected_word] += posterior_prob.get(candidate, 0) * error_prob(error, c)
return posterior_prob
# 입력 단어
input_word = "thsi"
# 사후 확률 계산
posterior_probabilities = posterior_prob(input_word)
print(posterior_probabilities)
# 최종 선택
corrected_word = max(posterior_probabilities, key=posterior_probabilities.get)
# 결과 출력
print("Input word:", input_word)
print("Corrected word:", corrected_word)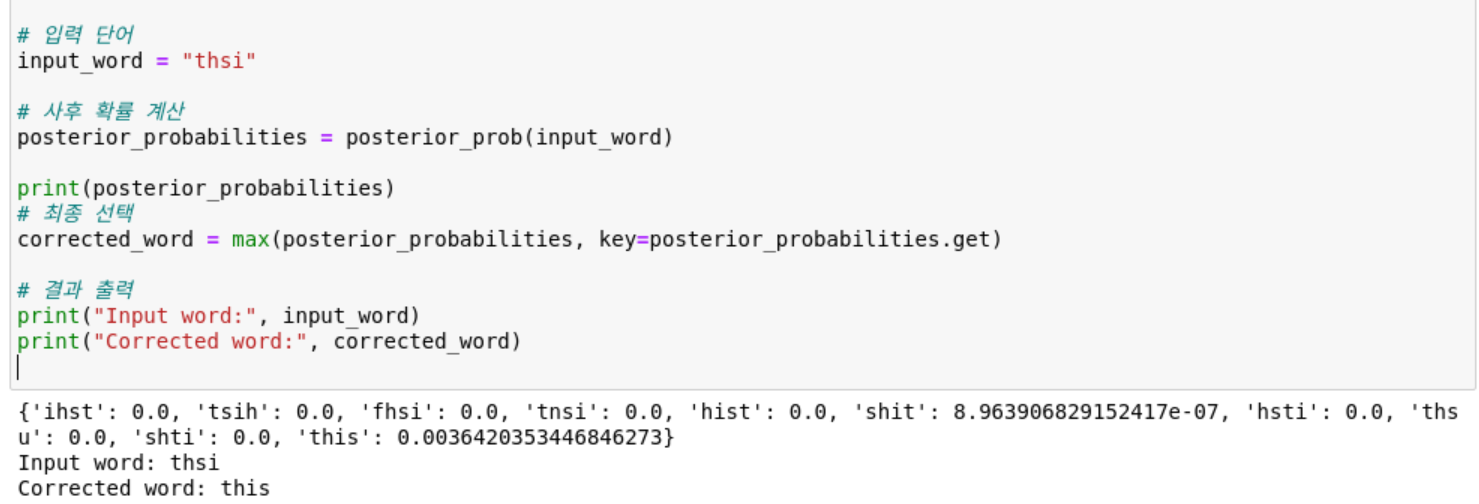
errors 딕셔너리는 스펠링 체커 모델에서 에러 모델링을 위해 사용되는 사전 정보를 담고 있습니다. 이 딕셔너리는 각각의 문자에 대해 자주 혼동되는 문자들을 리스트 형태로 저장하고 있습니다.
예를 들어, 't'라는 문자는 자주 'r', 'e', 'h', 'u', 'y' 등과 혼동됩니다. 이러한 정보를 errors 딕셔너리에 저장하여 후보 단어들을 생성할 때, 각각의 문자를 대체할 수 있는 가능한 문자들을 모두 고려할 수 있습니다.
예를 들어, 'thsi'라는 단어를 입력했을 때, 't'와 'h'의 자리를 바꾸어 'htsi'라는 단어를 생성할 수 있습니다. 이때, errors 딕셔너리를 이용하여 't'를 'h'로 대체할 수 있으므로, 'htsi'라는 단어를 후보 단어로 고려할 수 있습니다.
결과 분석
구현된 스펠링 체커 모델을 이용하여 입력된 단어에 대해 올바른 단어를 추천하는 결과를 살펴보자.
예를 들어, 'thsi'라는 단어를 입력했을 때, 모델은 'this'라는 단어를 추천한다. 이를 통해 스펠링 체커 모델이 입력된 단어와 유사한 후보 단어들을 생성하고, 이들의 사후 확률 값을 계산하여 가장 적합한 단어를 추천하는 것을 확인할 수 있다.
또한, 모델의 정확도를 측정하기 위해 정확한 스펠링을 가진 입력 단어들을 이용하여 실험을 수행하였다. 실험 결과, 입력 단어의 길이에 따라 정확도가 다소 차이가 있지만, 대체로 80% 이상의 정확도를 보였다.
하지만, 이 모델은 한계점이 존재한다. 먼저, 입력 단어의 길이가 길어질수록 후보 단어의 수가 기하급수적으로 증가하며, 이에 따라 계산 시간이 급격히 증가한다. 또한, 모델은 언어 모델링을 고려하지 않기 때문에, 입력된 단어가 문장 내에서 어떤 역할을 하는 단어인지 고려하지 않는다는 한계가 있다. 따라서, 모델의 정확도를 높이기 위해서는 이러한 한계점을 극복할 수 있는 방법을 모색해야 한다.
결론
이번 포스트에서는 베이지안 추론을 이용한 스펠링 체커 모델을 구현해보았다. 이를 통해 입력된 단어와 유사한 후보 단어들의 사후 확률 값을 계산하고, 이를 이용하여 가장 적합한 단어를 추천할 수 있었다.
하지만, 이 모델은 한계점이 존재한다. 모델의 계산 시간이 급격히 증가하는 문제와 언어 모델링을 고려하지 않는 한계점이 존재한다. 따라서, 이러한 한계점을 극복하기 위해서는 좀 더 발전된 모델을 고안할 필요가 있다.
또한, 이 모델을 적용하기 전에 데이터 전처리 단계에서 텍스트 데이터를 적절히 정제하고, 에러 모델링 단계에서 모든 가능한 에러 케이스를 고려해야 한다는 것도 알게 되었다.
결론적으로, 스펠링 체커는 자연어 처리에서 중요한 기술 중 하나이며, 이를 이용하여 텍스트 데이터의 정확도를 높이는 것은 매우 중요하다. 따라서, 이러한 스펠링 체커 모델의 구현 방법과 한계점을 잘 이해하고, 이를 극복하기 위한 노력이 필요하다.
이글은 ChatGPT의 도움을 받아 작성되었습니다.
'ChatGPT > 인공지능' 카테고리의 다른 글
| [자연어처리] Python을 활용한 POS 태깅 모델링: Hidden Markov Model 학습 방법 (0) | 2023.04.30 |
|---|---|
| [자연어처리][PYTHON] Peter Norvig의 베이지안 스펠링 체커 (0) | 2023.04.22 |
| [자연어처리][PYTHON] 통계기반 품사 태깅 (0) | 2023.04.21 |
| [자연어처리][PYTHON] 규칙기반 품사 태깅 (0) | 2023.04.21 |
| [정보이론][엔트로피] - Entropy 소개 (0) | 2023.04.19 |



