히스토그램의 개념과 용도
히스토그램이란?
히스토그램은 데이터의 분포를 시각화하는데 사용되는 차트입니다. 데이터의 빈도를 막대 형태로 표현하며, 가로 축에는 데이터의 구간, 세로 축에는 해당 구간에 속하는 데이터의 빈도 수를 나타냅니다. 각 막대의 높이는 해당 구간에 속하는 데이터의 개수를 나타내며, 전체 막대의 너비는 데이터의 전체 개수가 됩니다.
히스토그램을 통해 데이터의 분포, 중심 경향성, 이상치 등을 파악할 수 있습니다. 데이터의 분포가 어떠한 모양을 가지고 있는지, 데이터가 어느 범위에 몰려 있는지, 극단적인 값(이상치)이 있는지 등 시각적으로 파악할 수 있습니다.
히스토그램의 용도
히스토그램은 데이터 분석에서 다양한 용도로 사용됩니다. 주요 용도는 다음과 같습니다.
- 데이터 분포 확인: 데이터가 어떻게 분포되어 있는지 알아볼 수 있습니다. 정규 분포와 같은 특정한 형태를 가지는지, 왜곡되어 있는지 등을 확인할 수 있습니다.
- 이상치 탐지: 데이터의 이상치(Outlier)를 탐지하기 위해 히스토그램을 사용할 수 있습니다. 특정 구간에 비해 많이 높거나 낮은 값들은 이상치의 가능성이 높습니다.
- 동일한 변수 비교: 다른 데이터 집합의 히스토그램을 비교함으로써 두 데이터가 어떻게 다른지 확인할 수 있습니다. 두 데이터 집합 간의 분포 차이를 시각적으로 파악할 수 있습니다.
- 범주형 변수 분석: 범주형 변수의 분포를 확인할 때에도 히스토그램을 사용할 수 있습니다. 각 범주에 해당하는 데이터의 개수를 시각적으로 확인할 수 있습니다.
히스토그램은 데이터 탐색과 분석에 유용한 시각화 도구로서 널리 사용되며, 다양한 상황에서 활용할 수 있습니다. 다음으로 데이터 준비에 대해 알아보겠습니다.
데이터 준비
히스토그램을 그리기 위한 데이터 준비
히스토그램을 그리기 위해서는 분석하고자 하는 데이터를 먼저 준비해야 합니다. 데이터는 수치형 데이터이어야 하며, 데이터의 분포를 알아보고자 하는 변수에 해당하는 값들이어야 합니다.
일반적으로 파이썬에서는 데이터 처리와 분석에 유용한 패키지인 판다스(Pandas)를 많이 사용합니다. 판다스를 활용하여 데이터를 쉽게 불러오고 가공할 수 있습니다. 만약 데이터가 이미 다른 형태로 준비되어 있다면, 배열이나 리스트와 같은 파이썬의 자료형을 사용하여 데이터를 준비할 수도 있습니다.
Python의 NumPy를 이용하여 데이터 생성
데이터를 준비할 때에는 필요한 경우 Python의 NumPy 패키지를 사용하여 데이터를 생성할 수도 있습니다. NumPy는 파이썬에서 수치 계산을 위한 기능을 제공하는 패키지로, 다차원 배열을 다루는 기능을 제공합니다.
예를 들어, 0부터 100까지의 정수를 1000개 생성하고 싶다면 다음과 같이 NumPy를 사용할 수 있습니다.
import numpy as np
data = np.random.randint(0, 100, 1000)위 코드는 0부터 100까지의 정수 중에서 랜덤하게 1000개의 데이터를 생성하여 data 변수에 저장하는 예제입니다. 이렇게 생성된 데이터는 히스토그램을 그리기 위한 준비 데이터로 활용할 수 있습니다.
다음으로는 히스토그램 그리기에 대해 알아보겠습니다.
히스토그램 그리기
plt.hist() 함수 소개
히스토그램을 그리기 위해서는 Matplotlib 라이브러리의 pyplot 모듈을 사용합니다. 히스토그램을 그리기 위한 주요 함수는 plt.hist() 함수입니다. 이 함수는 데이터를 입력으로 받아 히스토그램을 그리는 기능을 제공합니다.
히스토그램 그리기 예제
아래는 plt.hist() 함수를 사용하여 히스토그램을 그리는 간단한 예제입니다.
import matplotlib.pyplot as plt
data = [1, 2, 3, 3, 4, 5, 5, 5, 6, 7, 8, 8, 9]
plt.hist(data)
plt.show()위 코드에서 data 변수에는 히스토그램을 그리기 위한 데이터가 저장되어 있습니다. plt.hist(data) 함수는 data 변수의 값을 이용하여 히스토그램을 그립니다. 마지막으로 plt.show() 함수를 호출하여 그래프를 출력합니다.

위 예제를 실행하면, 데이터의 분포를 히스토그램으로 표현한 차트가 화면에 출력됩니다. 히스토그램은 데이터의 분포를 시각적으로 파악할 수 있는 유용한 차트입니다.
다음으로는 히스토그램의 옵션 설정에 대해 알아보겠습니다.
히스토그램 옵션 설정
히스토그램은 다양한 옵션을 설정하여 그래프의 모양과 정보를 조절할 수 있습니다. 주요한 히스토그램 옵션을 살펴보겠습니다.
bins: 구간의 개수 설정
히스토그램을 그릴 때, 데이터를 구간으로 나누는데 이때 구간의 개수를 설정할 수 있습니다. 예를 들어, bins=5으로 설정하면 데이터를 5개의 구간으로 나누어 히스토그램을 그립니다. 구간의 개수를 적절하게 설정하는 것은 데이터의 분포를 잘 표현하는데 중요한 요소입니다.
plt.hist(data, bins=5)위 예제에서 bins 옵션에 5을 지정하여 데이터를 5개의 구간으로 나눠 히스토그램을 그립니다.
range: 표시할 범위 설정
히스토그램을 그릴 때, 범위를 설정하여 표시할 수도 있습니다. 이를 통해 특정 구간의 데이터 분포를 자세히 살펴볼 수 있습니다. 예를 들어, range=(0, 10)으로 설정하면 데이터 분포를 0부터 10까지의 범위로 제한하여 히스토그램을 그립니다.
plt.hist(data, range=(0, 10))위 예제에서 range 옵션에 (0, 10)을 지정하여 데이터 분포를 0부터 10까지의 범위로 제한하여 히스토그램을 그립니다.
density: 정규화 여부 설정
히스토그램은 상대적인 빈도를 나타내는데, 이 값을 상대적인 확률로 표현하고자 할 때 density=True로 설정할 수 있습니다. 이를 통해 히스토그램의 Y축은 확률로 표시됩니다.
plt.hist(data, density=True)위 예제에서 density 옵션에 True를 지정하여 히스토그램의 Y축을 확률로 표시합니다.
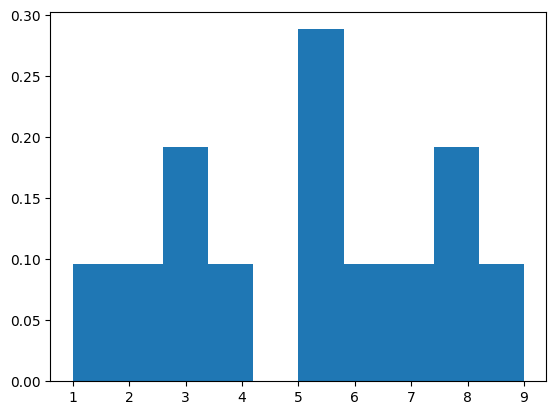
다중 히스토그램 그리기
히스토그램은 여러 개의 데이터를 동시에 비교하기 위해 다중으로 그릴 수도 있습니다. 이를 통해 각 데이터의 분포를 시각적으로 비교하거나 상호간의 관계를 알아볼 수 있습니다.
# 데이터 준비
data1 = np.random.normal(0, 1, 1000)
data2 = np.random.normal(2, 1, 1000)
# 다중 히스토그램 그리기
plt.hist(data1, alpha=0.5, label='Data 1')
plt.hist(data2, alpha=0.5, label='Data 2')
plt.legend()
plt.show()위의 예제에서는 두 개의 데이터, data1과 data2를 생성하고 다중 히스토그램을 그립니다. alpha 옵션을 이용하여 투명도를 조절하고, label을 이용하여 각 히스토그램의 레이블을 지정합니다. 마지막으로 legend() 함수를 호출하여 범례를 추가합니다.
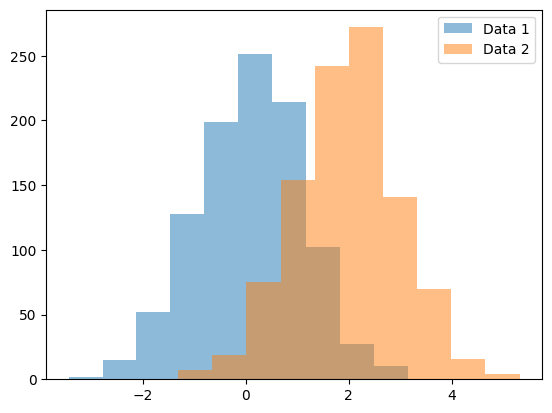
다중 히스토그램을 그릴 때에는 데이터의 개수와 구간의 개수를 맞추는 것이 중요합니다. 데이터 개수와 구간 개수가 다르면 종 모양이 아닌 비대칭적인 분포를 가질 수 있으니 주의해야 합니다.
히스토그램과 다른 차트 유형의 비교
히스토그램은 데이터의 분포를 나타내는데 많이 사용되지만, 다른 차트 유형들과도 비교해보면서 각각의 특징을 알아볼 수 있습니다.
히스토그램 vs 막대 그래프
- 히스토그램: 연속적인 값의 분포를 나타내는 데 사용됩니다. x축은 변수의 구간, y축은 변수의 빈도수(또는 밀도)를 나타냅니다.
- 막대 그래프: 이산적인 값들의 양을 비교하는데 사용됩니다. x축은 개별적인 변수, y축은 해당 변수의 값(또는 비율)을 나타냅니다.
히스토그램은 구간의 개수에 따라 모양이 달라질 수 있으며, 연속적인 분포를 잘 보여줍니다. 반면, 막대 그래프는 이산적인 변수들을 시각적으로 비교할 때 유용합니다.
히스토그램 vs 선 그래프
- 히스토그램: 변수의 분포를 나타내는 데 사용됩니다. 구간 별로 빈도수(또는 밀도)를 막대로 표현하는 것이 특징입니다.
- 선 그래프: 시간에 따른 값의 변화를 나타내는 데 사용됩니다. 데이터 포인트를 연결하여 선으로 표시합니다.
히스토그램은 변수의 분포를 파악하는 데 주로 사용되고, 선 그래프는 시계열 데이터나 추세를 확인할 때 유용합니다. 히스토그램은 구간별로 빈도수를 보여주는 반면, 선 그래프는 시간이나 순서에 따른 값을 표현합니다.
각 차트 유형은 데이터의 특성과 분석 목적에 따라 선택되어야 합니다. 히스토그램은 분포를 파악하고자 할 때 주로 사용되지만, 막대 그래프나 선 그래프와 함께 사용하여 데이터를 더 잘 이해할 수 있습니다.
히스토그램 활용 예시
히스토그램은 데이터의 분포를 시각화하기 위해 여러 가지 상황에서 활용될 수 있습니다. 아래는 몇 가지 히스토그램 활용 예시입니다.
1. 데이터 분포 확인
히스토그램은 주어진 데이터의 분포를 확인하는 데에 유용합니다. 예를 들어, 어떤 제품의 판매량 데이터가 있다면, 히스토그램을 통해 판매량의 분포를 확인하여 데이터가 어떻게 분포되어 있는지 알 수 있습니다. 이를 통해 판매량의 주요한 구간을 파악하거나 이상치를 식별할 수 있습니다.
2. 그룹간 비교
히스토그램을 여러 개 그려 그룹간 비교를 할 수도 있습니다. 예를 들어, 어떤 제품에 대한 고객 만족도를 조사한 결과가 여러 그룹으로 나누어져 있다면, 각 그룹에 대한 고객 만족도의 분포를 히스토그램으로 그려 비교할 수 있습니다. 이를 통해 어떤 그룹이 더 높은 만족도를 가지는지 확인할 수 있습니다.
3. 데이터 전처리
데이터 전처리 과정에서 히스토그램을 사용할 수도 있습니다. 예를 들어, 어떤 변수의 값에 이상치가 존재하는지 확인하고자 한다면, 해당 변수의 값들을 히스토그램으로 확인할 수 있습니다. 이상치는 히스토그램에서 극단적으로 높은 또는 낮은 값들로 확인될 수 있습니다.
4. 모델 성능 분석
머신러닝 모델의 성능을 분석할 때에도 히스토그램을 사용할 수 있습니다. 예를 들어, 분류 모델의 예측 확률을 히스토그램으로 그려 실제 클래스와 모델의 예측이 얼마나 일치하는지 확인할 수 있습니다. 이를 통해 모델의 분류 성능을 시각적으로 파악할 수 있습니다.
히스토그램은 데이터의 분포를 시각화하여 패턴을 파악하고, 그룹간 비교나 이상치 탐지 등에 활용할 수 있습니다. 데이터 분석의 다양한 단계에서 히스토그램을 활용하여 더 깊은 통찰력을 얻을 수 있습니다.
결론
히스토그램은 데이터 분포를 시각화하는 데에 유용한 도구입니다. 데이터의 분포를 확인하여 주요한 패턴이나 이상치를 파악할 수 있고, 그룹간 비교를 통해 차이점을 확인할 수도 있습니다. 또한, 데이터 전처리 과정에서 이상치를 탐지하거나 모델의 성능 분석에도 활용할 수 있습니다.
이 블로그 글에서는 히스토그램의 개념과 용도를 소개하고, 데이터 준비부터 히스토그램 그리기, 옵션 설정, 다중 히스토그램 그리기, 그리고 히스토그램과 다른 차트 유형 비교까지 다양한 내용을 다뤘습니다. 또한, 히스토그램을 실제 데이터에 적용하는 예시를 보여주었습니다.
히스토그램은 데이터 시각화 분야에서 많이 활용되는 차트 중 하나로, 데이터의 분포와 관련된 정보를 직관적으로 파악할 수 있습니다. 히스토그램을 잘 활용하여 데이터 분석과 시각화 작업을 진행하면 더 나은 인사이트를 얻을 수 있을 것입니다. 이제 여러분도 히스토그램을 활용하여 데이터를 효과적으로 분석하고 시각화할 수 있을 것입니다.
본 블로그 글은 G-ChatBot 서비스를 이용하여 AI(ChatGPT) 도움을 받아 작성하였습니다.
G-ChatBot
Our service is an AI chatbot service developed using OpenAI API. Our service features a user-friendly interface, efficient management of token usage, the ability to edit conversation content, and management capabilities.
gboysking.net
'Dev Language > Python' 카테고리의 다른 글
| [Python][Matplotlib] 바(bar) 차트 사용법 (0) | 2023.08.19 |
|---|---|
| [Python][Matplotlib] 선(Line) 차트 사용법 (0) | 2023.08.19 |
| [Python][Pandas] 판다스 데이터 프레임 기본 통계 ( describe...) (0) | 2023.08.13 |
| [Python][Pandas] 판다스 데이터 프레임 결합/합치기 ( concat, merge, join ) (0) | 2023.08.13 |
| [Python][Pandas] 판다스 소개 (0) | 2023.08.09 |



