이 코드는 양방향 LSTM 신경망을 사용하여 품사 태깅 모델을 학습하고 평가하는 파이썬 스크립트입니다. 스크립트는 NLTK 라이브러리에서 Treebank 말뭉치를 다운로드하고, 데이터를 전처리하며, Keras를 사용하여 모델 아키텍처를 정의하고, 모델을 학습하고 평가합니다.
배경
품사 태깅은 자연어 처리에서 중요한 작업 중 하나로, 문장 내 각 단어에 대한 품사 태그(명사, 동사, 형용사 등)를 할당하는 작업입니다. LSTM 신경망은 순차 데이터를 처리하는 데 유용한 재귀 신경망의 일종입니다. 양방향 LSTM은 입력 시퀀스를 앞뒤 양방향으로 처리하여, 과거와 미래의 입력에서도 문맥 정보를 파악할 수 있는 모델입니다.
Treebank 말뭉치는 품사 태깅 모델을 학습하고 평가하는 데 많이 사용되는 데이터셋으로, 39,000개 이상의 문장과 그에 해당하는 품사 태그가 포함되어 있습니다.
데이터 전처리
스크립트는 먼저 NLTK에서 Treebank 말뭉치를 다운로드하고, 문장과 그에 해당하는 품사 태그를 추출합니다. 그런 다음 말뭉치 내 고유한 단어와 품사 태그를 인덱스에 매핑하는 딕셔너리를 생성합니다. 이 딕셔너리를 사용하여 문장과 태그를 인덱스의 시퀀스로 변환하고, 모든 문장이 동일한 길이를 갖도록 패딩을 적용합니다. 마지막으로 품사 태그 시퀀스를 원-핫 인코딩합니다.
nltk.download('treebank')
# 데이터셋에서 문장과 품사 태그 추출
sentences = treebank.tagged_sents()
# 전처리된 데이터로부터 문장, 단어, 태그를 추출하여 중복을 제거하고 리스트로 저장합니다.
words = list(set([word for sentence in sentences for word, tag in sentence]))
tags = list(set([tag for sentence in sentences for word, tag in sentence]))
# 단어와 태그 각각에 대한 인덱스 딕셔너리를 생성합니다.
word2idx = {w: i + 2 for i, w in enumerate(words)} # 0: padding, 1: unknown word
tag2idx = {t: i + 1 for i, t in enumerate(tags)} # 0: padding
# 입력 데이터와 레이블 데이터를 생성합니다.
X = [[word2idx.get(word, 1) for word, tag in sentence] for sentence in sentences]
y = [[tag2idx[tag] for word, tag in sentence] for sentence in sentences]
# 각 문장의 길이를 동일하게 맞추기 위해 패딩을 추가합니다.
MAX_LEN = max(len(sentence) for sentence in X)
X = pad_sequences(X, maxlen=MAX_LEN, padding='post', truncating='post')
y = pad_sequences(y, maxlen=MAX_LEN, padding='post', truncating='post')
# 레이블을 one-hot 인코딩합니다.
y = to_categorical(y, num_classes=len(tag2idx) + 1)모델 아키텍처
모델은 단어 인덱스를 밀집 벡터로 매핑하는 임베딩 레이어로 시작하여, 양방향 LSTM 레이어로 이어집니다. 이후 소프트맥스 활성화 함수가 적용된 밀집 레이어가 사용되어 각 단어의 품사 태그를 예측합니다.
# Bi-LSTM 모델을 정의합니다.
model = Sequential()
model.add(Embedding(input_dim=len(word2idx)+2, output_dim=64, input_length=MAX_LEN, mask_zero=True))
model.add(Bidirectional(LSTM(units=128, return_sequences=True, dropout=0.5, recurrent_dropout=0.5)))
model.add(TimeDistributed(Dense(len(tag2idx)+1, activation='softmax')))
# 모델을 컴파일합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델을 학습합니다.
history = model.fit(X_train, y_train, validation_split=0.2, batch_size=32, epochs=10)
# 모델을 평가합니다.
score = model.evaluate(X_test, y_test, batch_size=32)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
모델은 단어 임베딩 층, 양방향 LSTM 층, TimeDistributed 및 Dense 층으로 구성됩니다. 임베딩 층은 입력으로 단어 인덱스 시퀀스를 받아 각 단어를 벡터로 변환합니다. LSTM 층은 이전 타임스텝의 출력을 현재 타임스텝의 입력으로 사용하여 시퀀스 정보를 추출합니다. TimeDistributed 층은 LSTM 층의 출력을 각 타임스텝마다 처리합니다. 마지막으로 Dense 층은 각 타임스텝의 출력을 입력으로 받아 최종 출력을 생성합니다.
모델은 Embedding 층에서 시작되며, 입력 차원의 크기는 단어 사전의 크기(len(word2idx)+2)와 embedding_dim(64)입니다. 모델의 output shape은 (batch_size, input_length, embedding_dim)이 됩니다. 다음으로, 양방향 LSTM 층이 쌓입니다. LSTM 층은 units(128)로 정의되며, dropout과 recurrent_dropout 모두 0.5로 설정됩니다. 이 LSTM 층은 return_sequences=True로 설정되어 각 시퀀스 타임스텝에 대한 출력을 반환합니다. 이 출력은 TimeDistributed 층을 통과하여, 각 시퀀스 타임스텝에 대한 최종 출력을 생성합니다.
전체 코드
import nltk
from nltk.corpus import treebank
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
nltk.download('treebank')
# 데이터셋에서 문장과 품사 태그 추출
sentences = treebank.tagged_sents()
# 전처리된 데이터로부터 문장, 단어, 태그를 추출하여 중복을 제거하고 리스트로 저장합니다.
words = list(set([word for sentence in sentences for word, tag in sentence]))
tags = list(set([tag for sentence in sentences for word, tag in sentence]))
# 단어와 태그 각각에 대한 인덱스 딕셔너리를 생성합니다.
word2idx = {w: i + 2 for i, w in enumerate(words)} # 0: padding, 1: unknown word
tag2idx = {t: i + 1 for i, t in enumerate(tags)} # 0: padding
# 입력 데이터와 레이블 데이터를 생성합니다.
X = [[word2idx.get(word, 1) for word, tag in sentence] for sentence in sentences]
y = [[tag2idx[tag] for word, tag in sentence] for sentence in sentences]
# 각 문장의 길이를 동일하게 맞추기 위해 패딩을 추가합니다.
MAX_LEN = max(len(sentence) for sentence in X)
X = pad_sequences(X, maxlen=MAX_LEN, padding='post', truncating='post')
y = pad_sequences(y, maxlen=MAX_LEN, padding='post', truncating='post')
# 레이블을 one-hot 인코딩합니다.
y = to_categorical(y, num_classes=len(tag2idx) + 1)
# 학습 데이터와 검증 데이터로 분리합니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
# Bi-LSTM 모델을 정의합니다.
model = Sequential()
model.add(Embedding(input_dim=len(word2idx)+2, output_dim=64, input_length=MAX_LEN, mask_zero=True))
model.add(Bidirectional(LSTM(units=128, return_sequences=True, dropout=0.5, recurrent_dropout=0.5)))
model.add(TimeDistributed(Dense(len(tag2idx)+1, activation='softmax')))
# 모델을 컴파일합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델을 학습합니다.
history = model.fit(X_train, y_train, validation_split=0.2, batch_size=32, epochs=10)
# 모델을 평가합니다.
score = model.evaluate(X_test, y_test, batch_size=32)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
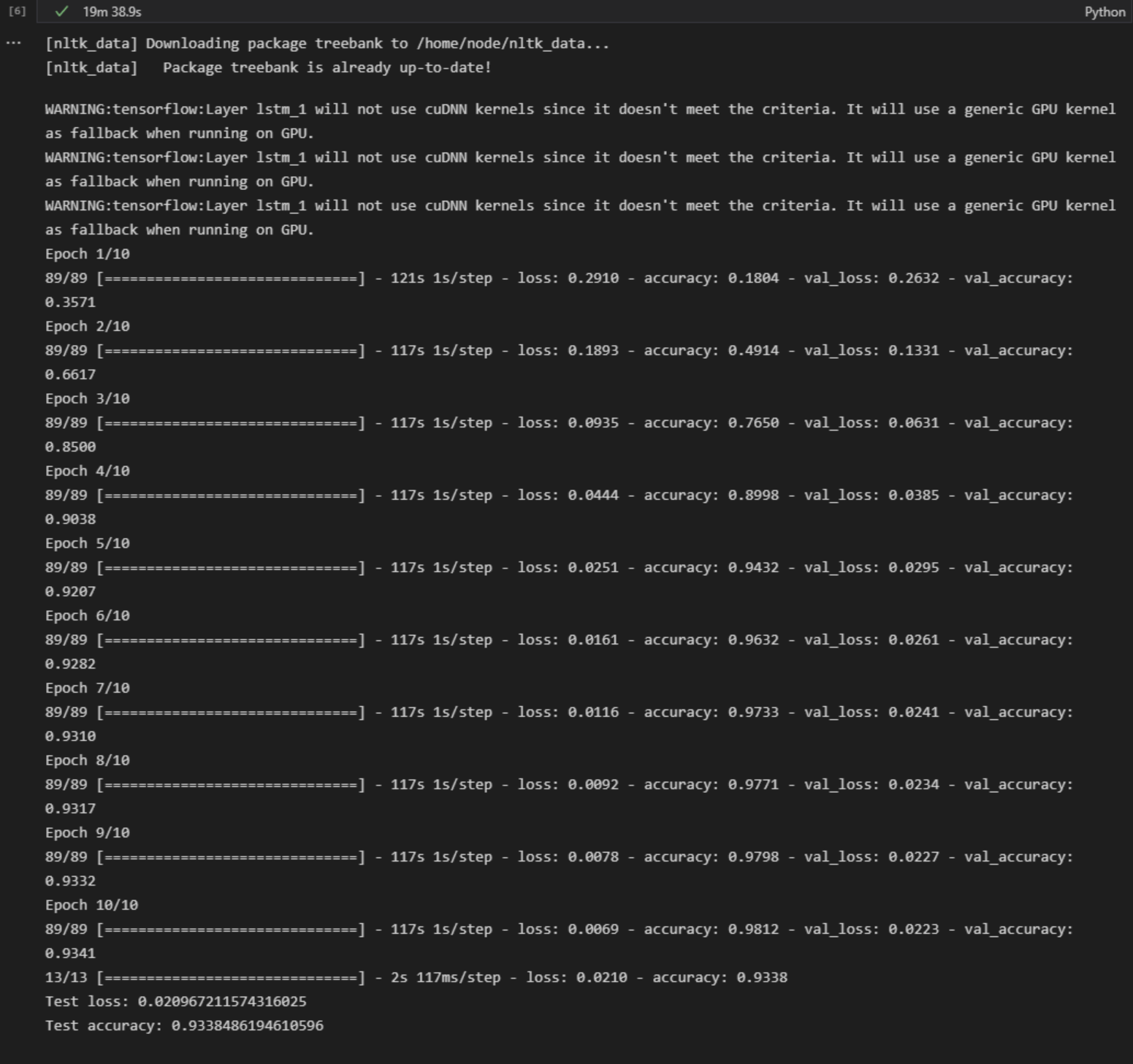
학습 및 평가
모델은 범주형 교차 엔트로피 손실과 Adam 옵티마이저를 사용하여 컴파일되며, 10 에포크 동안 32 배치 크기로 훈련됩니다. 검증 분할 및 배치 크기가 설정됩니다. 스크립트는 또한 테스트 세트에서 모델을 평가하고 손실과 정확도를 보고합니다.
결론
이 스크립트는 Keras와 NLTK를 사용하여 양방향 LSTM 네트워크를 사용하여 POS 태깅 모델을 전처리하고 학습하는 방법을 보여줍니다. 모델은 Treebank 말뭉치에서 높은 정확도를 달성하며, 하이퍼파라미터를 조정하거나 고급 기술을 사용하여 더욱 개선될 수 있습니다. 사용자는 스크립트를 수정하여 다른 데이터셋과 모델 아키텍처를 사용할 수 있습니다.
이글은 ChatGPT의 도움을 받아 작성되었습니다.
'ChatGPT > 인공지능' 카테고리의 다른 글
| [ML] 머신 러닝에서 사용되는 11가지 확률 분포 함수 소개 ( 파이썬 ) (0) | 2023.07.27 |
|---|---|
| [자연어처리] POS Tagging을 위한 Transformer 모델 구현하기 (0) | 2023.05.01 |
| [자연어처리] 파이썬으로 CRF를 이용한 품사 태깅 구현하기 (0) | 2023.04.30 |
| [자연어처리] Python을 활용한 POS 태깅 모델링: Hidden Markov Model 학습 방법 (0) | 2023.04.30 |
| [자연어처리][PYTHON] Peter Norvig의 베이지안 스펠링 체커 (0) | 2023.04.22 |


